


Linux系统性能优化:七个实战经验
来源:twt社区IT社区
链接:https://mp.weixin.qq.com/s/Rey0gSnnj-zoAEwE6J-Gjw



1、影响Linux系统性能的因素一般有哪些?
@zhaoxiaoyong081
平安科技
资深工程师:
Linux系统的性能受多个因素的影响。以下是一些常见的影响Linux系统性能的因素:
-
CPU负载:CPU的利用率和负载水平对系统性能有直接影响。高CPU负载可能导致进程响应变慢、延迟增加和系统变得不稳定。
-
内存使用:内存是系统运行的关键资源。当系统内存不足时,可能会导致进程被终止、交换分区使用过多以及系统性能下降。
-
磁盘I/O:磁盘I/O性能是影响系统响应时间和吞吐量的重要因素。高磁盘I/O负载可能导致延迟增加、响应变慢和系统性能下降。
-
网络负载:网络流量的增加和网络延迟会对系统性能产生影响。高网络负载可能导致网络延迟增加、响应变慢和系统资源竞争。
-
进程调度:Linux系统使用进程调度器来管理和分配CPU资源。调度算法的选择和配置会影响进程的优先级和执行顺序,从而影响系统的响应能力和负载均衡。
-
文件系统性能:文件系统的选择和配置对磁盘I/O性能有影响。不同的文件系统可能在性能方面有所差异,适当的文件系统选项和调整可以改善系统性能。
-
内核参数:Linux内核有许多可调整的参数,可以影响系统的性能和行为。例如,TCP/IP参数、内存管理参数、文件系统缓存等。适当的内核参数调整可以改善系统的性能和资源利用率。
-
资源限制和配额:在多用户环境中,资源限制和配额的设置可以控制每个用户或进程可使用的资源量。适当的资源管理可以避免某些进程耗尽系统资源而导致性能问题。
2、工作中有没有快速排除故障的办法?
@zhaoxiaoyong081 平安科技 资深工程师:
1.CPU 性能分析
利用 top、vmstat、pidstat、strace 以及 perf 等几个最常见的工具,获取 CPU 性能指标后,再结合进程与 CPU 的工作原理,就可以迅速定位出 CPU 性能瓶颈的来源。
比如说,当你收到系统的用户 CPU 使用率过高告警时,从监控系统中直接查询到,导致 CPU 使用率过高的进程;然后再登录到进程所在的 Linux 服务器中,分析该进程的行为。你可以使用 strace,查看进程的系统调用汇总;也可以使用 perf 等工具,找出进程的热点函数;甚至还可以使用动态追踪的方法,来观察进程的当前执行过程,直到确定瓶颈的根源。
2.内存性能分析
可以通过 free 和 vmstat 输出的性能指标,确认内存瓶颈;然后,再根据内存问题的类型,进一步分析内存的使用、分配、泄漏以及缓存等,最后找出问题的来源。
比如说,当你收到内存不足的告警时,首先可以从监控系统中。找出占用内存最多的几个进程。然后,再根据这些进程的内存占用历史,观察是否存在内存泄漏问题。确定出最可疑的进程后,再登录到进程所在的 Linux 服务器中,分析该进程的内存空间或者内存分配,最后弄清楚进程为什么会占用大量内存。
3.磁盘和文件系统 I/O 性能分析
当你使用 iostat ,发现磁盘 I/O 存在性能瓶颈(比如 I/O 使用率过高、响应时间过长或者等待队列长度突然增大等)后,可以再通过 pidstat、 vmstat 等,确认 I/O 的来源。接着,再根据来源的不同,进一步分析文件系统和磁盘的使用率、缓存以及进程的 I/O 等,从而揪出 I/O 问题的真凶。
比如说,当你发现某块磁盘的 I/O 使用率为 100% 时,首先可以从监控系统中,找出 I/O 最多的进程。然后,再登录到进程所在的 Linux 服务器中,借助 strace、lsof、perf 等工具,分析该进程的 I/O 行为。最后,再结合应用程序的原理,找出大量 I/O 的原因。
4.网络性能分析
而要分析网络的性能,要从这几个协议层入手,通过使用率、饱和度以及错误数这几类性能指标,观察是否存在性能问题。比如 :
在链路层,可以从网络接口的吞吐量、丢包、错误以及软中断和网络功能卸载等角度分析;
在网络层,可以从路由、分片、叠加网络等角度进行分析;
在传输层,可以从 TCP、UDP 的协议原理出发,从连接数、吞吐量、延迟、重传等角度进行分析;
3、Linux环境下,怎么排查os中系统负载过高的原因瓶颈?
@zhaoxiaoyong081 平安科技 资深工程师:
在Linux环境下排查系统负载过高的原因和瓶颈,可以采取以下步骤:
-
使用top或htop命令观察系统整体负载情况。查看load average的值,分别表示系统在1分钟、5分钟和15分钟内的平均负载。如果负载值超过CPU核心数量的70-80%,表示系统负载过高。
-
使用top或htop命令查看CPU占用率。观察哪些进程占用了大量的CPU资源。如果有某个进程持续高CPU占用,可能是引起负载过高的原因之一。
-
使用free命令查看系统内存使用情况。观察内存的使用量和剩余量。如果内存使用量接近或超过物理内存容量,可能导致系统开始使用交换空间(swap),进而影响系统性能。
-
使用iotop命令查看磁盘I/O使用情况。观察磁盘读写速率和占用率。如果磁盘I/O负载过高,可能导致系统响应变慢。
-
使用netstat命令或类似工具查看网络连接情况。观察是否存在大量的网络连接或网络流量。如果网络连接过多或网络流量过大,可能影响系统的性能。
-
检查日志文件。查看系统日志文件(如/var/log/messages、/var/log/syslog)以及应用程序日志,寻找任何异常或错误信息,可能有助于确定导致负载过高的问题。
-
使用perf或strace等工具进行进程级别的性能分析。这些工具可以帮助你跟踪进程的系统调用、函数调用和性能瓶颈,进一步确定导致负载过高的具体原因。
-
检查系统的配置和参数设置。审查相关的配置文件(如/etc/sysctl.conf、/etc/security/limits.conf)和参数设置,确保系统的设置与实际需求相匹配,并进行适当的调整。
4、Linux怎么找出占用负载top5的进程及主要瓶颈在哪个资源(CPU or 内容 or 磁盘 IO)?
@zhaoxiaoyong081 平安科技 资深工程师:
CPU 使用排名
ps aux --sort=-%cpu | head -n 5
内存 使用排名
ps aux --sort=-%mem | head -n 6
IO 使用排名
iotop -oP
@zwz99999 dcits 系统工程师:
查看最占用 CPU 的 10 个进程
#ps aux|grep -v USER|sort +2|tail -n 10
查看最占用内存的 10 个进程
#ps aux|grep -v USER|sort +3|tail -n 10
io
5、Linux的内存计算不准如何解决?
@Acdante
HZTYYJ
技术总监:
free是执行时间的瞬时计数,/proc/memory内存是实时变化的。
而且free会把缓存和缓冲区内存都计入使用内存,所以会导致看到的可用内存少很多。
准确值的话,建议结合多种监控指标和命令手段去持续观测内存情况。
如:htop 、 nmon 、 syssta、top等,可以结合运维软件和平台,而非站在某个时间点,最好是有一定时间的性能数据积累,从整体趋势和具体问题点位去分析。
内存只是一个资源指标,使用内存的调用才是问题根源。
@zhaoxiaoyong081 平安科技 资深工程师:
在一些情况下,通过ps或top命令查看的内存使用累计值与free命令或/proc/meminfo文件中的内存统计值之间可能存在较大差异。这可以由以下原因导致:
-
缓存和缓冲区:Linux系统使用缓存和缓冲区来提高文件系统性能。这些缓存和缓冲区占用的内存会被标记为"cached"(缓存)和"buffers"(缓冲区)类型。然而,这些内存并不一定是实际被进程使用的内存,而是被内核保留用于提高IO性能。因此,ps或top命令显示的内存使用累计值可能包括了这些缓存和缓冲区,而free命令或/proc/meminfo中的统计值通常不包括它们。
-
共享内存:共享内存是一种特殊的内存区域,多个进程可以访问和共享它。ps或top命令显示的内存使用累计值可能会包括共享内存的大小,而free命令或/proc/meminfo中的统计值通常不会将其计算在内。
-
内存回收:Linux系统具有内存回收机制,可以在需要时回收未使用的内存。这意味着一些进程释放的内存可能不会立即反映在ps或top命令显示的内存使用累计值中。相比之下,free命令或/proc/meminfo中的统计值通常更及时地反映实际的内存使用情况。
综上所述,ps或top命令显示的内存使用累计值和free命令或/proc/meminfo中的内存统计值之间的差异通常是由于缓存和缓冲区、共享内存以及内存回收等因素造成的。如果你需要更准确地了解进程实际使用的内存,建议参考free命令或/proc/meminfo中的统计值,并结合其他工具和方法进行综合分析
@wenwen123 项目经理:
在Linux中,可能会出现内存计算不准确的情况,导致ps、top命令中的内存使用累计值与free命令或/proc/meminfo中的内存统计值之间存在较大差异。这种差异可能由以下原因导致:
-
共享内存:共享内存是多个进程之间共享的一块内存区域,用于进程间通信。共享内存不会被ps、top等工具计算在内存使用量中,因为它们只统计进程的私有内存使用量。因此,如果进程使用了大量的共享内存,它的内存使用量在工具中显示的数值可能较低。
-
缓存和缓冲区:Linux系统会将一部分内存用于缓存和缓冲区,以提高文件系统和IO操作的性能。这些缓存和缓冲区的内存在ps、top等工具中被视为可回收的,因此它们通常不计入进程的内存使用量中。但是,在free命令或/proc/meminfo中,这些缓存和缓冲区的内存会被纳入统计。
-
内存回收机制:Linux内核具有内存回收机制,根据需要自动回收和分配内存。这可能导致在ps、top等工具显示的内存使用量和free命令或/proc/meminfo中的统计值之间存在差异。这种差异通常是正常的,并且Linux会动态管理内存以满足系统的需求。
针对内存计算不准确的问题,关注共享内存是合理的。共享内存的使用可能对进程的内存使用量造成影响,但不会被ps、top等工具计算在内存使用量中。如果需要更准确地了解进程的内存使用情况,可以使用专门的工具,如pmap、smem等,这些工具可以提供更详细和准确的内存统计信息。
6、 Swap现在的应用场景还有哪些?
@zhaoxiaoyong081 平安科技 资深工程师:
虽然现代计算机的内存容量越来越大,但交换分区(swap)仍然在某些场景下具有重要的应用。以下是一些使用交换分区的常见场景:
-
内存不足:交换分区作为内存不足时的后备机制,用于将不经常使用或暂时不需要的内存页面转移到磁盘上。当物理内存(RAM)不足以容纳所有活动进程和数据时,交换分区可以提供额外的虚拟内存空间,以避免系统发生内存耗尽错误(Out of Memory)。
-
休眠/睡眠模式:交换分区在某些操作系统中用于支持休眠(hibernation)或睡眠(suspend)模式。当计算机进入休眠或睡眠状态时,系统的内存状态会被保存到交换分区中,以便在唤醒时恢复到先前的状态。
-
虚拟化环境:在虚拟化环境中,交换分区可以用于虚拟机的内存管理。当宿主机的物理内存不足时,虚拟机的内存页面可以被交换到宿主机的交换分区,以提供额外的内存空间。
-
内存回收和页面置换:交换分区可以用于内存回收和页面置换算法。当操作系统需要释放物理内存以满足更紧急的需求时,它可以将不活动的内存页面置换到交换分区中,以便将物理内存分配给更重要的任务或进程。
7、在Linux tcp方面有什么调优经验或案例?
@zhanxuechao 数字研究院 咨询专家:
centos7-os-init.sh





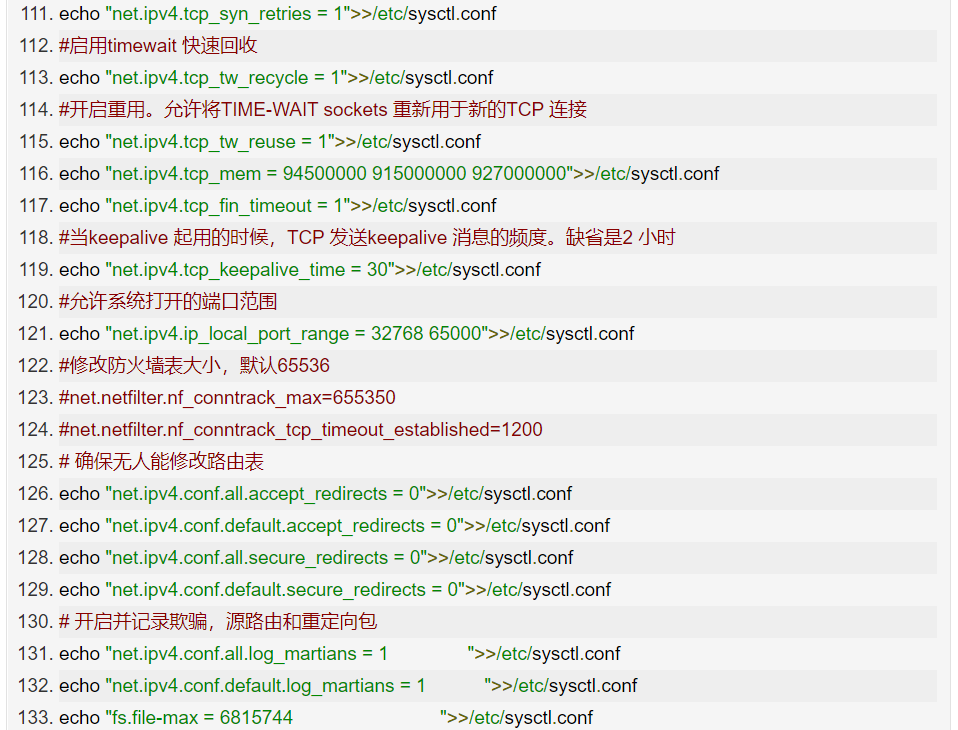





@zhaoxiaoyong081 平安科技 资深工程师:
TCP 优化,分三类情况详细说明:
第一类,在请求数比较大的场景下,你可能会看到大量处于 TIME_WAIT 状态的连接,它们会占用大量内存和端口资源。这时,我们可以优化与 TIME_WAIT 状态相关的内核选项,比如采取下面几种措施。
增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets ,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max。
减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放它们所占用的资源。
开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。
增大本地端口的范围 net.ipv4.ip_local_port_range 。这样就可以支持更多连接,提高整体的并发能力。
增加最大文件描述符的数量。你可以使用 fs.nr_open 和 fs.file-max ,分别增大进程和系统的最大文件描述符数;或在应用程序的 systemd 配置文件中,配置 LimitNOFILE ,设置应用程序的最大文件描述符数。
第二类,为了缓解 SYN FLOOD 等,利用 TCP 协议特点进行攻击而引发的性能问题,你可以考虑优化与 SYN 状态相关的内核选项,比如采取下面几种措施。
增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog ,或者开启 TCP SYN Cookies net.ipv4.tcp_syncookies ,来绕开半连接数量限制的问题(注意,这两个选项不可同时使用)。
减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries。
第三类,在长连接的场景中,通常使用 Keepalive 来检测 TCP 连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的 Keepalive 探测间隔和重试次数,一般都无法满足应用程序的性能要求。所以,这时候你需要优化与 Keepalive 相关的内核选项,比如:
缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time;
缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl;
减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes。
春招已经开始啦,大家如果不做好充足准备的话,春招很难找到好工作。
送大家一份就业大礼包,大家可以突击一下春招,找个好工作!






 京公网安备 11010802033920号
京公网安备 11010802033920号