本次Hot Chips正好是第30届,开幕的欢迎词中简单回顾了会议的历史。比较有趣的是用关键词的方式对比了每十年发生的变化。
Hot Chips 1

Hot Chips 10

Hot Chips 20

Hot Chips 30

今年展示内容最多的三家是:Google(3个talk),Nvidia(3个talk)和Xilinx(4个talk,包括深鉴)。Google不仅talk多,参会的人也不少,感觉确实招募了大量IC领域的人才。Nvidia仍然很霸气,这次Xavier和NvSwith都透露了更多的细节,Xilinx在新CEO上任后也在发力。我会在后面分别介绍他们的工作。另外,ML仍然是热点,除了两个专门的ML
session之外,几乎所有的talk都会涉及到ML/AI,所以我也会写一篇文章专门介绍一下ML相关内容。在详细讨论这些话题之前,先来个流水账吧。
•••
Tutorial
会议正式开始之前的周末是Tutorial时间,上午的区块链相关内容基本是不知所云,就不说了。下午是“Architectures for Accelerating Deep Neural Nets”,包括来自Xilinx的Overview,MIT韩松的“Accelerating Inference at the Edge”,Cerebras的“Accelerating Training in the Cloud”。Tutorial主要是基础,不过内容还是比较丰富,大家如果感兴趣可以去找来PPT看看。
Xilinx的讲座里面有如下一页挺有意思,是在说模型准确度和运算代价(主要由模型设计和量化精度决定)之间的平衡。图中的例子是说,使用Resnet18,8b/8b量化,实现10.68%的错误率;但如果使用Resnet50,虽然模型复杂了,但可以在2b
weight下达到9.86%的错误率,而此时的计算代价从286减少到127。这种trade-off必须考虑更多的因素,意味着需要探索的设计空间会更大,而这可能成为未来神经网络设计的趋势。

在这几个讲座里,我主要关注的是Cerebras这个比较神秘的Startup。不过他们的讲座基本没有涉及任何自己的东西。除了在最后提了一下他们眼里未来的Training加速目标,我们也可以把这个看作是他们要实现的目标吧。

在讲未来的时候他们也把值得关注的竞争对手放在了一起,还专门强调了排序完全是按字母顺序的。

最后,他们还聊了几句关于Benchmark Cheats的问题,有点意思,大家自己去看看吧。
•••
Day 1
进入正式会议的第一天,第一个session是“Mobile/Pwr Efficient Processors”:有来自三星的“Samsung’s Exynos-M3 CPU”,Google的“ The Pixel Visual Core”,以及UCBerkeley的“BROOM: An open-source Out-of-Order processor with resilient low-voltage operation in 28nmCMOS”。
这次三星透露的M3已经有相关的文章进行了比较详细的介绍,我就不在多说了。讲演中有一页提到“Conditionalpredictor improvements including more weights for Neural Net”,我不是很明白,了解的朋友可以留言介绍一下。
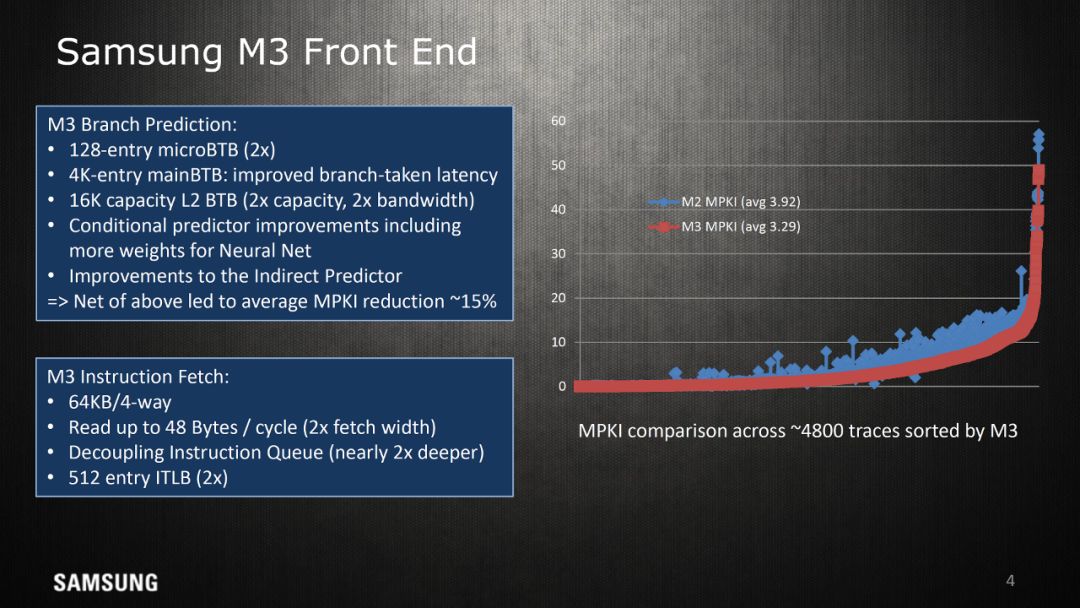
UC
Berkeley的Broom是一个开源的RISC-V设计,其芯片部分我就不多分析了,比较值得讨论的是所谓敏捷开发的问题。这个talk多次强调他们是两个人4个月实现tape-out,还专门提出了Agile
Hardware Development的话题,这可能和他们的导师David Patterson有一定的关系。我们之前的文章(黄金时代)中简单谈到这个问题,DavidPatterson也经常把硬件的敏捷开发和RSIC-V/Chisel联系在一起。

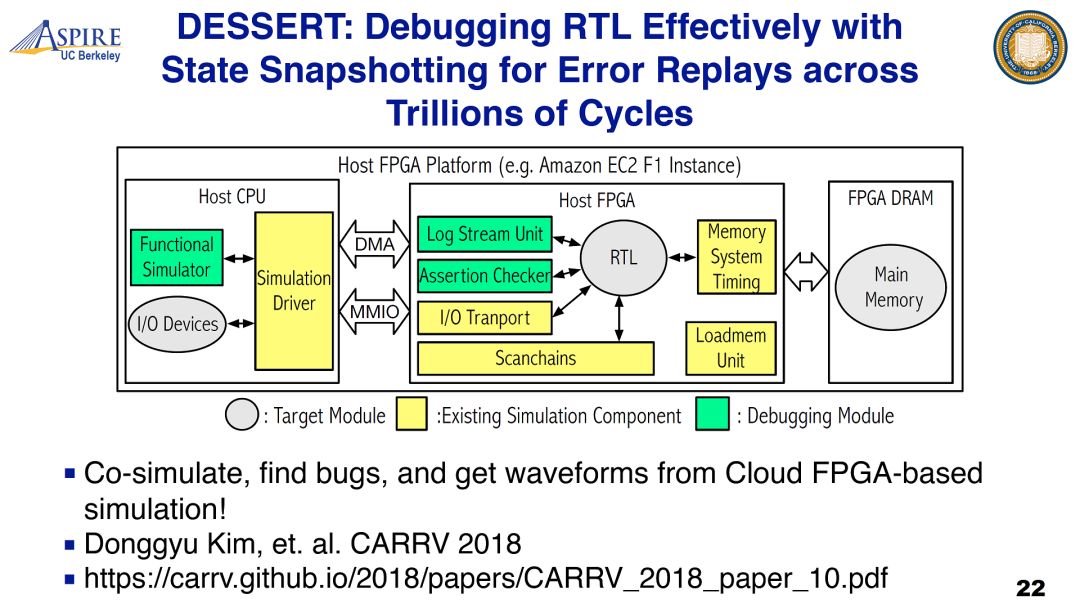
个人感觉这是有一定误导性的,如果仔细看BROOM芯片的设计,这个项目覆盖的内容是比较少的,基本就是BOOM核加cache再加一个简单的到FPGA的I/O接口。因此在设计流程中,需要验证的范围很小。加之是研究项目,综合后端这些任务也可以尽量简化。在这个talk中分享的一些经验顶多算一些技巧。在实际的商业项目是实现硬件的敏捷开发还是非常困难的问题,不是一两个点上的改进就能解决的。最近我们也在研究这个问题,欢迎大家找我讨论。这个talk中提到的DESSERT项目看起来挺有意思,可以关注一下。
第二个session是“Graphics Solutions”:有来自Intel的“Intel’s High Performance Graphics solutions inthin and light mobile form factors”和AMD的“Delivering a new level of Visual Performance inand SoC – AMD Raven Ridge APU”,这个部分没有Nvidia参与,按照我粗浅的认识,好像也没看到什么亮点,就略过吧。
在这之后是大会第一个Keynote:Spectre/Meltdown。讲演阵容很强大,新晋图灵奖得主John Hennessy亲自开场,分析了CPU架构漏洞爆发后,我们对安全问题新的认识。整个Keynote非常详细的分析了这类sidechannel attack的机制和更多的潜在威胁,并从软件和硬件的角度分析了问题的成因和可能的解决方法。总得来说,在过去几十年间,体系结构领域追求的主要是性能和效率,而这次事件确实大大提高了大家对安全性的关注度。但现在谈彻底的解决方法还为时尚早,这基本还是个没有答案的问题。目前能做的基本还是减轻它带来的影响,更多的是Mitigation。大家在后面的讨论中甚至提到要在计算机教育中增加大家对安全性的认识等等。
在讲演中有几个点还是比较有意思,和大家分享一下。首先是对问题成因的一个分析:软硬件割裂的问题。其实在AI系统设计中,我们已经看到更多的软硬件联合设计的趋势。相信未来不仅在应对安全问题的时候,在计算系统设计的时候会更多的采用全栈垂直模型来分析和解决问题。其实也很自然,分割可以简化问题;但优化则经常需要打破边界。当然这也对方法学,工具和模型提出了更高的要求,我们应该会先在Domain-specific的设计中进行更多的实践。这同样也是我们现在在研究的问题,欢迎大家的讨论。

另一个点是对解决方法的讨论,比如这部分最后一个talk提出的Architecture2.0的问题。我们目前遇到的安全性问题,不能说是微结构设计的Bug,而要解决它就需要新的架构规范,虽然我们还不知道是什么样的规范。

对于解决方法的两个讨论:1. 通过使用更多的硬件加速,减少对Speculation的依赖(目前漏洞的主要基础);2. 利用开源硬件的透明特点提高安全性。

 当然,总得来说安全问题目前还没有解决方案。但按照Hennessy和Patterson的说法,安全方面的挑战也将是体系结构黄金时代的主要驱动之一。
当然,总得来说安全问题目前还没有解决方案。但按照Hennessy和Patterson的说法,安全方面的挑战也将是体系结构黄金时代的主要驱动之一。
第三个session是“IoT/Edge Computing”,首先是来自Harvard的“SMIV: A 16nm SoC with Efficient and FlexibleDNN Acceleration for Intelligent IoT Devices”。这是个研究项目,主要特点是在SoC中加入了嵌入式FPGA,和支持Cache Coherence的硬件加速器。感觉ARM给了很多支持,主要是围绕ARM的东西在做试验。这里就不细讲了。和之前的BROOM项目一样这里也提到了快速开发的问题,但基本也都是业界比较常用的方式。其中的HLS不知道具体的方法,但从SystemC开始的话应该还是描述了比较详细的硬件特征的,而不是从更抽象的描述开始,大概和Chisel方法类似。

这部分第二个talk来自,MIT
Vivienne Sze团队,“Navion: An Energy-Efficient Visual-InertialOdometry
Accelerator for Micro Robotics and
Beyond”。这是一个视觉SLAM项目,这个应用领域我不是很熟悉,不过据说他们是第一家做芯片的。Sze做的Eyeress项目和DNN
hardware tutorial在AI芯片领域还是很有影响力的,我之前也不止一次做过介绍。这次见到真人,最大的感受就是说话好快。
第一天最后一个部分是“Security”,包括来自微软的“The Hardware Security Platform Behind AzureSphere “和来自Google的“ Titan: Google’s Root-of-Trust Security Silicon ”。前者主要是一个基于云的IoT安全平台,而后者则主要是用专用安全芯片“Titan”解决云端芯片的可信性问题。这个领域我不太熟悉,就不多做评论了。不过Google最后提到会开源它们的“Titan”芯片。如前所述,在安全领域,开放和开源是一种增加可信度比较好的方式。

•••
Day 2
会议第二天的主要内容包括ML,Xilinx也贡献了好几个talk,这些我会在后面的文章中介绍。这里先看看几个相对独立的talk。
第一个是在“Switching Fabrics and FPGA Architectures”的session中,来自Barefoot Networks的“Programmable Forwarding Planes at Terabit/s Speeds“。在现在的大规模计算环境中网络和网络芯片的作用是非常重要的。这个talk可以作为这个领域一个非常好的综述。

另外,这个talk中提到的”get programmability without the penalty“,是个非常好的问题。

“New Technology” session中,Nantero介绍了“Architecture for Carbon Nanotube Based
Memory(NRAM)
”,即基于碳纳米管的新型存储。这个NRAM和我们之前听到的多种新型NVM存储还不太一样,其目标是替换现在的DRAM。它的基本原理是通过控制碳纳米管的弯曲来控制连接状态。在一个区域里有很多这里的碳纳米管,不同的连接状态可以改变这个区域的电阻,从而实现‘0’,‘1’值的存储。目前看到的各种指标基本可以说是完美,因此在问题环节中的第一个问题就是“It sounds too good to be true. Did I miss something?”不过讲演的哥们估计天天面对这个问题,应对还是非常自如的。结论是除了一点小的限制,基本就是这么牛。所以,我们外行也不好评价了,保持关注吧。
第二天最后一个session是“Server Processors “,这本来应该是Hot Chips的一个重头戏。在做演讲四家,IBM(The IBM POWER9 Scale Up Processor),Fujitsu(Fujitsu High Performance CPU for the Post-KComputer),NEC(Vector Engine Processor of NEC’s Brand-New supercomputer SX-AuroraTSUBASA)和Intel(Next Generation Intel Xeon(R) Scalable processor: Cascade Lake),两家日本公司讲的内容比较丰富一些,不过语言还是有点问题,听的不是很清楚。IBM和Intel讲的东西新的信息不多,而且在大家提问中也经常以无法透露来回答,总体感觉有点无聊。
•••
其它
除了正式的演讲之外,会议还有一些Demo和Poster。正好在会议期间SiFive宣布了一个RISC-V+NVDLA(NVDLA在FPGA上)的系统,好像也有展示。

其它的比如深鉴也做了很好的Demo,可能以后就是和Xilinx一起了。
Poster里面,我本来是比较关注阿里的“Ultra Low Latency and High Performance Deep LearningProcessor “。可惜负责的同学嘴很紧,什么都不说,所以也只能看看作罢。
•••
总得来说,这次Hot Chps 30确实是非常热闹的,注册人数又创了新高。这应该和AI芯片的火热以及非传统芯片公司自研芯片的趋势有很大关系。会上可以看到很多熟悉的面孔,也遇到一些读者,挺有意思。但愿这确实是“黄金时代“的开启,而不是虚假繁荣的投影。
上一篇:芯片的未来在还要靠摩尔定律吗?
下一篇:国产X86芯片公司兆芯高管表示:新流片性能看齐Intel i5
推荐阅读
史海拾趣
FOCI Fiber Optic Communications Inc.公司发展的五个故事
故事一:成立与初创期
FOCI Fiber Optic Communications Inc.(以下简称FOCI)成立于1995年,由台湾工业技术研究院(工研院)的核心团队创立。这家公司自诞生之初就专注于光纤互连技术的发展,致力于设计、制造和销售高性能的光纤组件和集成模块。初创时期,FOCI凭借其对光纤技术的深刻理解和市场需求的敏锐洞察,逐步在市场上站稳脚跟,成为光纤通信领域的一股新兴力量。
故事二:技术创新与突破
FOCI在发展过程中,始终将技术创新视为企业发展的核心驱动力。公司不断投入研发资源,在光纤耦合器、PLC分配器、薄膜粗波分复用/密集波分复用以及多光纤电缆组装模块等领域取得了多项技术突破。这些技术创新不仅提升了产品的性能和质量,还大幅降低了生产成本,使得FOCI的产品在市场上更具竞争力。
故事三:与奇景光电的战略合作
2024年,半导体解决方案无晶圆厂巨头奇景光电(Himax Technologies)宣布向FOCI投入5.22亿新台币(折合约为1610万美元)的资金。这次投资不仅是两家公司财务合作的结果,更是双方在技术融合与应用拓展上迈出的重要一步。根据合作协议,FOCI的共封装光学器件(CPO)与奇景光电的晶圆级光学器件(WLO)将被整合到多芯片模块中,这些模块将广泛应用于高性能计算、云服务器、人工智能等多个领域。
故事四:全球化布局与市场拓展
随着全球光纤通信市场的快速发展,FOCI积极实施全球化战略,不断拓展国际市场。公司通过参加国际展会、建立海外销售网络等方式,将高性能的光纤组件和集成模块带到了世界各地。特别是在光纤到户(FTTH)和云计算领域,FOCI的产品因其高效、低成本的特性而广受欢迎,成功在全球市场占据了一席之地。
故事五:子公司设立与多元化发展
为了进一步拓展业务领域和市场份额,FOCI在国内设立了多家子公司,如中山上诠通信科技有限公司等。这些子公司不仅继承了FOCI在光纤通信领域的深厚底蕴和技术优势,还根据当地市场需求进行了产品和服务的本地化调整。同时,FOCI还积极探索多元化发展路径,涉足光纤高速数据传输技术开发设计、研发和咨询等多个领域,为公司未来的持续发展奠定了坚实基础。
在产品研发和技术创新的同时,艾迈斯(AMASS)公司也注重品牌建设和市场推广。公司积极参加各种行业展会和交流活动,与业界同行建立了广泛的合作关系。同时,艾迈斯还通过广告宣传、媒体报道等多种方式提升品牌知名度和影响力。这些努力使得艾迈斯在电子行业中的地位逐渐提升,成为了业内颇具影响力的品牌之一。
随着电子行业的快速发展,市场竞争也日益激烈。为了保持领先地位,EMLSI公司开始实施全球化战略。公司先后在亚洲、欧洲和北美等地建立了生产基地和研发中心,与当地企业建立了紧密的合作关系。这一战略不仅让EMLSI能够更快地了解市场需求和技术趋势,还为公司带来了更多的商业机会和合作伙伴。
为了进一步扩大市场份额,Curtis Industries公司积极拓展市场布局。公司在全球范围内设立了多个生产基地和研发中心,以便更好地满足不同地区客户的需求。同时,公司还加强了与上下游企业的合作,形成了完整的产业链。这些举措不仅提升了公司的产能和研发实力,还为公司带来了更多的商业机会。
随着全球化进程的加速,Datakey Electronics意识到单靠国内市场已经无法满足公司的长远发展需求。于是,公司积极寻求国际合作机会,与国际知名企业建立战略合作伙伴关系,共同开发新产品、开拓新市场。通过国际合作,Datakey Electronics不仅提高了自身的技术水平和产品竞争力,还成功将产品推向了国际市场。
Black Box意识到,在电子行业中,不同的行业细分市场有着不同的需求和特点。因此,公司决定采取深耕行业细分市场的策略,针对金融、教育、制造等不同行业提供定制化的解决方案。这一策略使Black Box能够更好地满足客户的实际需求,提高了客户满意度和忠诚度。
|
【日经BP社报道】夏普日前成功开发出可将消耗电流比过去削减20%~30%的A-D转换器电路技术。可根据温度和工作频率等情况,将A-D转换器的消耗电流控制到正常运行所需的最低水平。该公司现已试制出14位A-D转换器,且已证实可正常运行。这次的技术不 ...… 查看全部问答∨ |
|
|
本信息来自合作QQ群:电子工程师技术交流(12425841) 群主在坛子ID:Kata各位大侠,遇到pcb布线问题。请教大家两个问题3kvdc跟地间的安全距离多少?pcb上的最小距离多少高压放电是高电势跟低电势放电吧?… 查看全部问答∨ |
|
|
看到一些帖子上说STM32,100+脚以上的会有VREF脚,以下的就没有了,,我用的是100脚的,是STM3210B的开发板,我量了下,VREF+怎么是8mv的?… 查看全部问答∨ |
STM32 + RA8875 + AT070TN92 + 触摸屏 + USB + C++Builder6.0,全部开源 源代码及原理图,视频演示: http://www.ourdev.cn/bbs/bbs_content.jsp?bbs_sn=5047511&bbs_id=9999&bbs_page_no=1… 查看全部问答∨ |
|
毕业设计用TMS320C6678EVM多核实现自适应滤波器,核心部分是自适应滤波算法,看了一个月一点进展也没有,论坛里有用C6678的吗? 用C6678怎么进行多核编程呢,LMS算法又该怎么分配给多核进行处理呢? 看到文档中提到多核处理模式有两种:M ...… 查看全部问答∨ |











 ATTINY804-SSN
ATTINY804-SSN





 京公网安备 11010802033920号
京公网安备 11010802033920号